Working with GenBank Files
GenBank is the NHI genetic sequence database of DNA sequences. GenBank is part of the International Nucleotide Sequence Database Collaboration, which comprises the DNA DataBank of Japan (DDBJ), the European Molecular Biology Laboratory (EMBL), and GenBank at NCBI.
GenBank Format
GenBank format is text-based. Following is an example of a GenBank record; note that only the beginning of the record is shown:
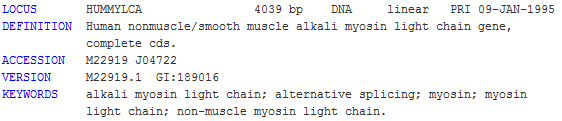
It is a multisequence format and each sequence is terminated by a double-slash sign ('//'). For detailed information on GenBank format, please consult the NHI GenBank site.
GenBank files and extensions
By default, files terminated by the extensions "gb" and "genbank" are recognized by the Explorer and displayed with a GenBank icon (![]() ). Associations between GenBank files and extensions can be adjusted in the Options > Miscellaneous > Files panel.
). Associations between GenBank files and extensions can be adjusted in the Options > Miscellaneous > Files panel.
Viewing GenBank files in the Explorer
To view the sequences contained in a Genbank file, click on the plus ('+') sign in front of the node as follow:
![]()
if GenBeans fails to parse a sequence, an error sign will be shown in the explorer:
The other records of the file will be valid as long as the double-slash separators ('//') are properly located.
Contextual menu
You can access the contextual menu by right-clicking the mouse on the sequence node or the file node:
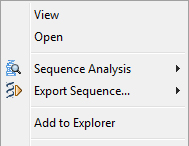
• Open: Open the Genbank file in the Editor at the first line of the sequence.
• Sequence Analysis: Access to varied sequence analyses such as translation, restriction analysis, etc.
• Export Sequence: Export to a new file in varied formats.
The GenBank editor
Opening files in the Editor
To open a GenBank file, either double-click on the corresponding node in the Explorer or choose the menu File > Open from the main menu to access the file dialog. Once opened in the editor, the GenBank file is automatically parsed and highlighted appropriately. The color schema can be adjusted in the Fonts & Colors category of the Options panel. When an error in the format is encountered, a special red highlight is shown in the editor as in the following example:
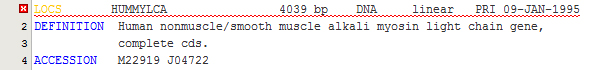
Editing GenBank records
By default, GenBank files cannot be edited manually. The reason is double, GenBank format is complex and requires a precise knowledge of each tag formatting and is at best generated by a software; secondly a record can be easily corrupted. Let say, for example, that you remove a few nucleotides from a record by hand, any feature location that extends to the end of the sequence becomes obsolete since their end value is now bigger than the sequence length; these features also need to be adjusted manually. If you need to edit a record anyway, first unlock editing by clicking the locking state button (![]() ) in the editor toolbar; edit your sequence manually; at any time click on the refresh button (
) in the editor toolbar; edit your sequence manually; at any time click on the refresh button (![]() ) located in the same toolbar. In our example, after editing the sequence data, GenBeans parses the record and adjusts all feature locations internally; a sequence refresh simply synchronizes the record with GenBeans internal sequence representation and fixes all locations automatically. Note that when sequence data are modified, GenBeans compares the new data with the previous one and calculate the part of the sequence that has changed. All features overlapping this section will be removed during a refresh action. Finally relock the editing by clicking the locking state button (
) located in the same toolbar. In our example, after editing the sequence data, GenBeans parses the record and adjusts all feature locations internally; a sequence refresh simply synchronizes the record with GenBeans internal sequence representation and fixes all locations automatically. Note that when sequence data are modified, GenBeans compares the new data with the previous one and calculate the part of the sequence that has changed. All features overlapping this section will be removed during a refresh action. Finally relock the editing by clicking the locking state button (![]() ) in the editor toolbar.
) in the editor toolbar.
Contextual menu
Right-click anywhere in a record to access a specific contextual menu.
![]() See Also
See Also